Project Overview
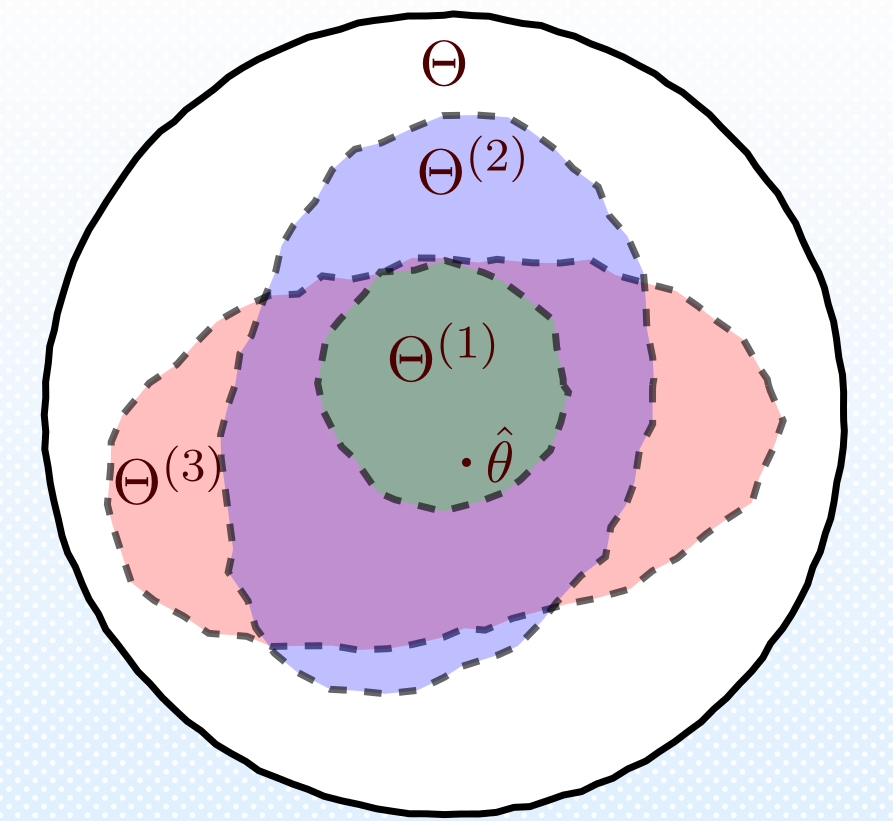
Overview
This work seeks to view fair machine learning across groups through the lens of multi-task learning, where we seek not just bounds on the total risk, but rather on the risk of each group, and thus we employ a localization-based analysis approach to better understand the regularizing effects of fair learning over multiple groups, which results in stronger guarantees for the generalization error of the cardinal fairness objective, as well as the generalization error of each group. This analysis rigorously quantifies the tradeoff between the variance-reducing and the bias-increasing effects of joint training. Crucially, this lets us explore the impact of pooling data across groups on minority groups, which benefit most from additional data (due to overfitting to small sample sizes), but are most susceptible to being ignored by common machine learning objectives (due to small impact on objective functions).